2026

DocHop: Benchmarking Out-of-domain Multi-hop Reasoning in Information-Dense Documents
Zhuoran Yu, Le Thien Phuc Nguyen, Jaden Park, Xinyi Gu, Zexue He, Soochahn Lee, Rogerio Feris, Yong Jae Lee
Proceedings of the International Conference on Machine Learning (ICML), 2026
DocHop: Benchmarking Out-of-domain Multi-hop Reasoning in Information-Dense Documents
Zhuoran Yu, Le Thien Phuc Nguyen, Jaden Park, Xinyi Gu, Zexue He, Soochahn Lee, Rogerio Feris, Yong Jae Lee
Proceedings of the International Conference on Machine Learning (ICML), 2026
2025

See, Hear, and Understand: Benchmarking Audiovisual Human Speech Understanding in Multimodal Large Language Models
Le Thien Phuc Nguyen*, Zhuoran Yu*, Samuel Low Yu Hang, Subin An, Jeongik Lee, Yohan Ban, SeungEun Chung, Thanh-Huy Nguyen, JuWan Maeng, Soochahn Lee, Yong Jae Lee (* equal contribution)
Findings of The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR Findings), 2026
Workshop on Emerging Directions in Data for Multimodal Foundation Models (DataMFM) @ CVPR 2026 Oral
Interactive Physical AI Workshop (IPA) @ CVPR 2026
See, Hear, and Understand: Benchmarking Audiovisual Human Speech Understanding in Multimodal Large Language Models
Le Thien Phuc Nguyen*, Zhuoran Yu*, Samuel Low Yu Hang, Subin An, Jeongik Lee, Yohan Ban, SeungEun Chung, Thanh-Huy Nguyen, JuWan Maeng, Soochahn Lee, Yong Jae Lee (* equal contribution)
Findings of The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR Findings), 2026
Workshop on Emerging Directions in Data for Multimodal Foundation Models (DataMFM) @ CVPR 2026 Oral
Interactive Physical AI Workshop (IPA) @ CVPR 2026
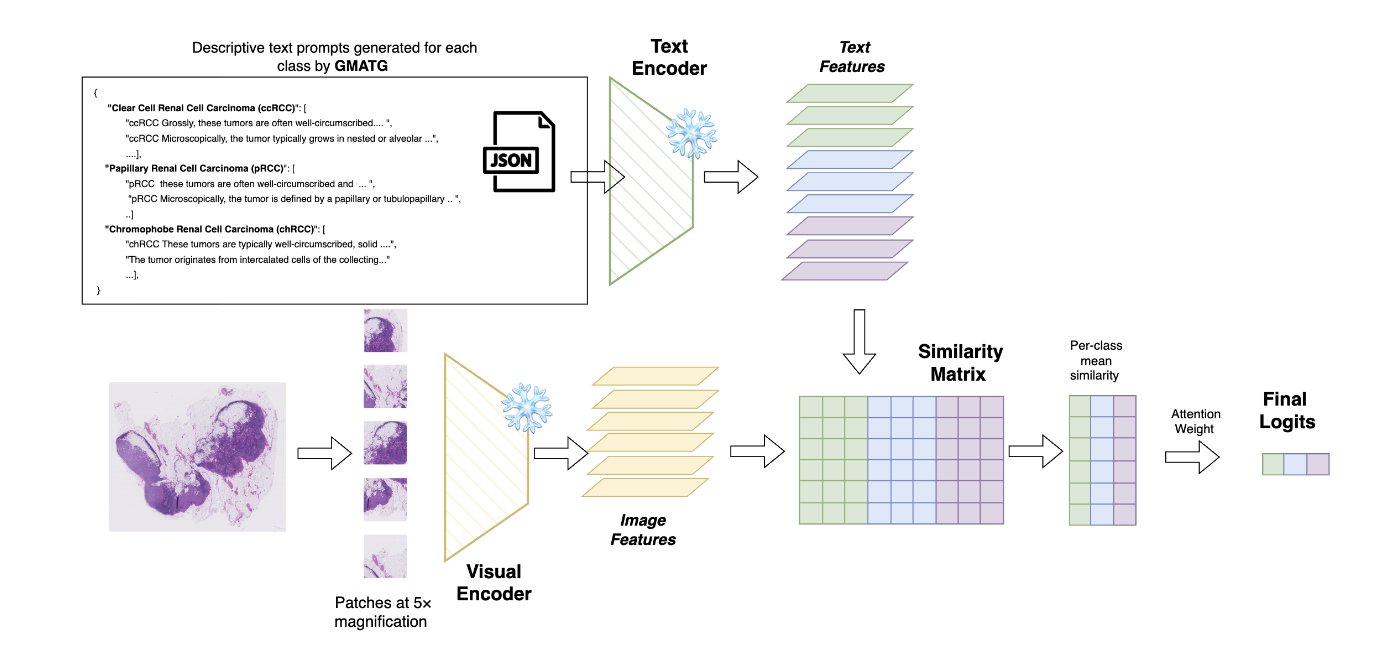
GMAT: Grounded Multi-Agent Clinical Description Generation for Text Encoder in Vision-Language MIL for Whole Slide Image Classification
Ngoc Bui Lam Quang, Nam Le Nguyen Binh, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Quan Nguyen, Ulas Bagci
ELAMI Workshop @ the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2025
GMAT: Grounded Multi-Agent Clinical Description Generation for Text Encoder in Vision-Language MIL for Whole Slide Image Classification
Ngoc Bui Lam Quang, Nam Le Nguyen Binh, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Quan Nguyen, Ulas Bagci
ELAMI Workshop @ the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2025
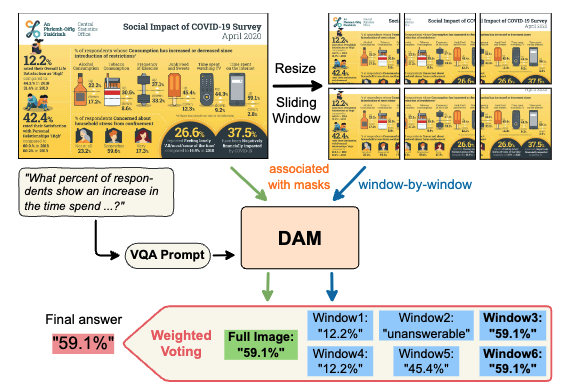
Describe Anything Model for Visual Question Answering on Text-rich Images
Yen-Linh Vu, Dinh-Thang Duong, Truong-Binh Duong, Anh-Khoi Nguyen, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Jianhua Xing, Xingjian Li, Tianyang Wang, Ulas Bagci, Min Xu
VisionDocs Workshop @ the International Conference on Computer Vision (ICCV), 2025
Describe Anything Model for Visual Question Answering on Text-rich Images
Yen-Linh Vu, Dinh-Thang Duong, Truong-Binh Duong, Anh-Khoi Nguyen, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Jianhua Xing, Xingjian Li, Tianyang Wang, Ulas Bagci, Min Xu
VisionDocs Workshop @ the International Conference on Computer Vision (ICCV), 2025

UniTalk: Towards Universal Active Speaker Detection in Real World Scenarios
Le Thien Phuc Nguyen*, Zhuoran Yu*, Khoa Quang Nhat Cao, Yuwei Guo, Tu Ho Manh Pham, Tuan Tai Nguyen, Toan Ngo Duc Vo, Lucas Poon, Soochahn Lee, Yong Jae Lee (* equal contribution)
arXiv, 2025
UniTalk: Towards Universal Active Speaker Detection in Real World Scenarios
Le Thien Phuc Nguyen*, Zhuoran Yu*, Khoa Quang Nhat Cao, Yuwei Guo, Tu Ho Manh Pham, Tuan Tai Nguyen, Toan Ngo Duc Vo, Lucas Poon, Soochahn Lee, Yong Jae Lee (* equal contribution)
arXiv, 2025

LASER: Lip Landmark Assisted Speaker Detection for Robustness
Le Thien Phuc Nguyen*, Zhuoran Yu*, Yong Jae Lee (* equal contribution)
The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026 Oral
LASER: Lip Landmark Assisted Speaker Detection for Robustness
Le Thien Phuc Nguyen*, Zhuoran Yu*, Yong Jae Lee (* equal contribution)
The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026 Oral