
 Affiliated with the University of North Carolina at Chapel Hill
Affiliated with the University of North Carolina at Chapel HillCS PhD Student
Hi, my name is Le Thien Phuc Nguyen.
I am from Vietnam, and I am currently a CS PhD student at the University of North Carolina at Chapel Hill, advised by Professor Zhongzheng (Jason) Ren . Also, I am honored to be co-advised by Professor Yong Jae Lee at the University of Wisconsin - Madison.
Previously, I was an Undergraduate Researcher at Wisconsin AI Vision Lab (WAIV), University of Wisconsin-Madison, working with Professor Yong Jae Lee . At WAIV, I am fortunate to work with my mentor, Dr. Zhuoran Yu , who taught me a lot.
I received my B.S. in Computer Science, Data Science, Math, and Statistics (4 majors) from the University of Wisconsin-Madison in 2026.
My research interests focus on multimodal models, with a particular emphasis on video, audio, image, and large language models (LLMs). Specifically, I have expertise in multimodal learning and representation. Currently, I am interested in Multimodal Agentic AI and Embodied AI.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
University of North Carolina at Chapel HillCS Ph.D. StudentAug. 2026 - present
-
 University of Wisconsin - MadisonB.S. in Computer Science, Data Science, Math, and StatisticsSep. 2022 - May. 2026
University of Wisconsin - MadisonB.S. in Computer Science, Data Science, Math, and StatisticsSep. 2022 - May. 2026
Honors & Awards
-
WACV 2026 Oral Presentation2026
-
Gold medal in the ICPC North Central North America (NCNA)2023
-
Silver medal in the ICPC North Central North America (NCNA)2022
-
Third prize in the Vietnam National Olympiad in Informatics2022
-
Second prize in the ICPC Vietnam National Round2021
-
Second prize in the Vietnam National University Olympiad in Informatics2021
News
Selected Publications (view all )

DocHop: Benchmarking Out-of-domain Multi-hop Reasoning in Information-Dense Documents
Zhuoran Yu, Le Thien Phuc Nguyen, Jaden Park, Xinyi Gu, Zexue He, Soochahn Lee, Rogerio Feris, Yong Jae Lee
Proceedings of the International Conference on Machine Learning (ICML), 2026
DocHop: Benchmarking Out-of-domain Multi-hop Reasoning in Information-Dense Documents
Zhuoran Yu, Le Thien Phuc Nguyen, Jaden Park, Xinyi Gu, Zexue He, Soochahn Lee, Rogerio Feris, Yong Jae Lee
Proceedings of the International Conference on Machine Learning (ICML), 2026

See, Hear, and Understand: Benchmarking Audiovisual Human Speech Understanding in Multimodal Large Language Models
Le Thien Phuc Nguyen*, Zhuoran Yu*, Samuel Low Yu Hang, Subin An, Jeongik Lee, Yohan Ban, SeungEun Chung, Thanh-Huy Nguyen, JuWan Maeng, Soochahn Lee, Yong Jae Lee (* equal contribution)
Findings of The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR Findings), 2026
Workshop on Emerging Directions in Data for Multimodal Foundation Models (DataMFM) @ CVPR 2026 Oral
Interactive Physical AI Workshop (IPA) @ CVPR 2026
See, Hear, and Understand: Benchmarking Audiovisual Human Speech Understanding in Multimodal Large Language Models
Le Thien Phuc Nguyen*, Zhuoran Yu*, Samuel Low Yu Hang, Subin An, Jeongik Lee, Yohan Ban, SeungEun Chung, Thanh-Huy Nguyen, JuWan Maeng, Soochahn Lee, Yong Jae Lee (* equal contribution)
Findings of The IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR Findings), 2026
Workshop on Emerging Directions in Data for Multimodal Foundation Models (DataMFM) @ CVPR 2026 Oral
Interactive Physical AI Workshop (IPA) @ CVPR 2026
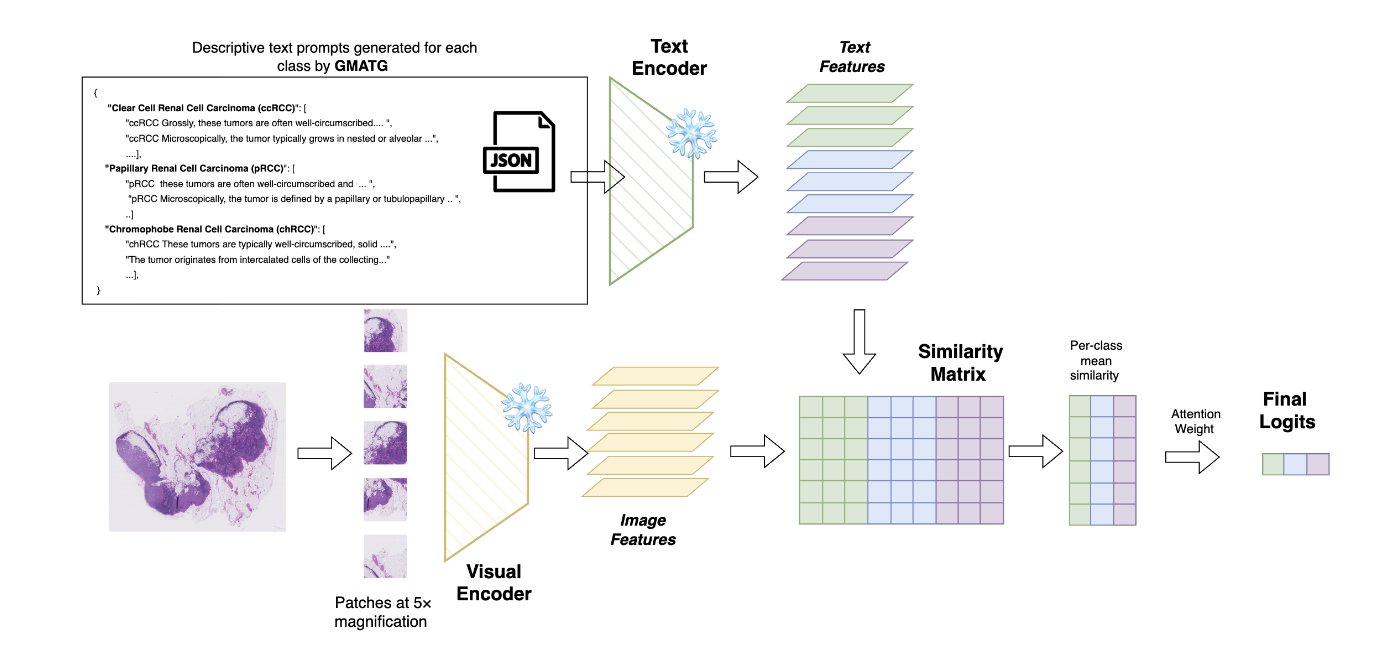
GMAT: Grounded Multi-Agent Clinical Description Generation for Text Encoder in Vision-Language MIL for Whole Slide Image Classification
Ngoc Bui Lam Quang, Nam Le Nguyen Binh, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Quan Nguyen, Ulas Bagci
ELAMI Workshop @ the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2025
GMAT: Grounded Multi-Agent Clinical Description Generation for Text Encoder in Vision-Language MIL for Whole Slide Image Classification
Ngoc Bui Lam Quang, Nam Le Nguyen Binh, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Quan Nguyen, Ulas Bagci
ELAMI Workshop @ the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), 2025
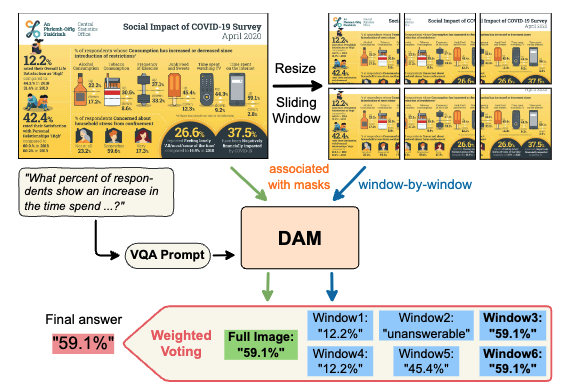
Describe Anything Model for Visual Question Answering on Text-rich Images
Yen-Linh Vu, Dinh-Thang Duong, Truong-Binh Duong, Anh-Khoi Nguyen, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Jianhua Xing, Xingjian Li, Tianyang Wang, Ulas Bagci, Min Xu
VisionDocs Workshop @ the International Conference on Computer Vision (ICCV), 2025
Describe Anything Model for Visual Question Answering on Text-rich Images
Yen-Linh Vu, Dinh-Thang Duong, Truong-Binh Duong, Anh-Khoi Nguyen, Thanh-Huy Nguyen, Le Thien Phuc Nguyen, Jianhua Xing, Xingjian Li, Tianyang Wang, Ulas Bagci, Min Xu
VisionDocs Workshop @ the International Conference on Computer Vision (ICCV), 2025

UniTalk: Towards Universal Active Speaker Detection in Real World Scenarios
Le Thien Phuc Nguyen*, Zhuoran Yu*, Khoa Quang Nhat Cao, Yuwei Guo, Tu Ho Manh Pham, Tuan Tai Nguyen, Toan Ngo Duc Vo, Lucas Poon, Soochahn Lee, Yong Jae Lee (* equal contribution)
arXiv, 2025
UniTalk: Towards Universal Active Speaker Detection in Real World Scenarios
Le Thien Phuc Nguyen*, Zhuoran Yu*, Khoa Quang Nhat Cao, Yuwei Guo, Tu Ho Manh Pham, Tuan Tai Nguyen, Toan Ngo Duc Vo, Lucas Poon, Soochahn Lee, Yong Jae Lee (* equal contribution)
arXiv, 2025

LASER: Lip Landmark Assisted Speaker Detection for Robustness
Le Thien Phuc Nguyen*, Zhuoran Yu*, Yong Jae Lee (* equal contribution)
The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026 Oral
LASER: Lip Landmark Assisted Speaker Detection for Robustness
Le Thien Phuc Nguyen*, Zhuoran Yu*, Yong Jae Lee (* equal contribution)
The IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2026 Oral